

故事背景:
因为平时上班摸鱼用手机看小说,那些小说网站总是会挂载各种yellow广告,要是被同时看到就不好了,而且有时候点击下一章加载超级慢(我网络是正常的),于是乎就有了下面事情。
开始干饭:
首先要有自己云主机和域名,然后有一定java开发基础,推荐使用jfinal极速开发,真的很快。
项目架构:jfinal4.9+layui+mysql8
我的想法
爬取小说网站上面想要的书籍,存入到mysql数据库里面,然后把这一个java项目打包部署到云虚拟机上面,这样以后我用手机就可以随时随地愉快的看小说了,从根源上杜绝各种广告等等。个人后期测试使用,速度超级流畅,网络请求没有一丁点卡顿,可能我数据量比较少,并发数就我一个人,所以服务器压力也小。
下面只贴出核心代码。
1、找一个小说网站
要爬取数据:该书籍的所有目录和章节内容
查看要爬取的书籍目录,如下图,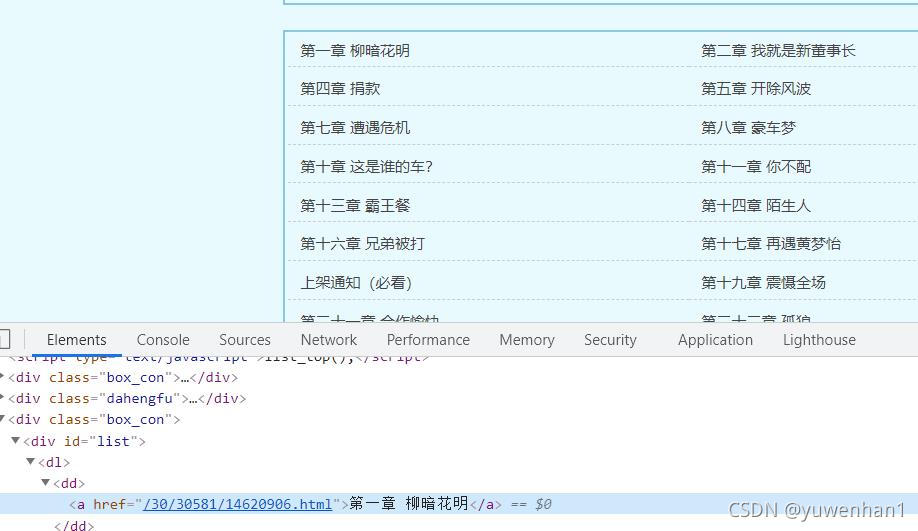
根据该目录html结构,我们java代码就可以这样子写:
public Document getDocument(String url){
//获取请求链接
Connection conn=Jsoup.connect(url).timeout(5000);
//请求头设置
conn.header("Accept", "text/html,application/xhtml+xml,application/xml;q=0.9,image/webp,*/*;q=0.8");
conn.header("Accept-Encoding", "gzip, deflate, sdch");
conn.header("Accept-Language", "zh-CN,zh;q=0.8");
conn.header("User-Agent", "Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/55.0.2883.87 Safari/537.36");
try {
return conn.get();
} catch (IOException e) {
throw new RuntimeException(e);
}
}
//获取所有章节标题和链接//url为该小说目录网址
public void getAllTitle(String url) {
int i=0;
Document doc=util1.getDocument(url);//获取document对象
Element ml=doc.getElementById("list");//获取目录列表
Elements allA=ml.select("a");//获取a标签
for(Element e:allA) {
System.out.println("该章节的标题:"+e.html());
System.out.println("该章节的url:"+e.attr("href"));
++i;
}
System.out.println("一共采集到:"+i);
}java项目采用jsoup爬取网页内容,相关语法请自行查看官网,jsoup官方文档
下面给出maven依赖
<dependency> <groupId>org.jsoup</groupId> <artifactId>jsoup</artifactId> <version>1.13.1</version> </dependency>
采集结果:可以看到已经成功了,那你就可以把数据存入数据库中
接下来采集文章正文:
分析正文html结构,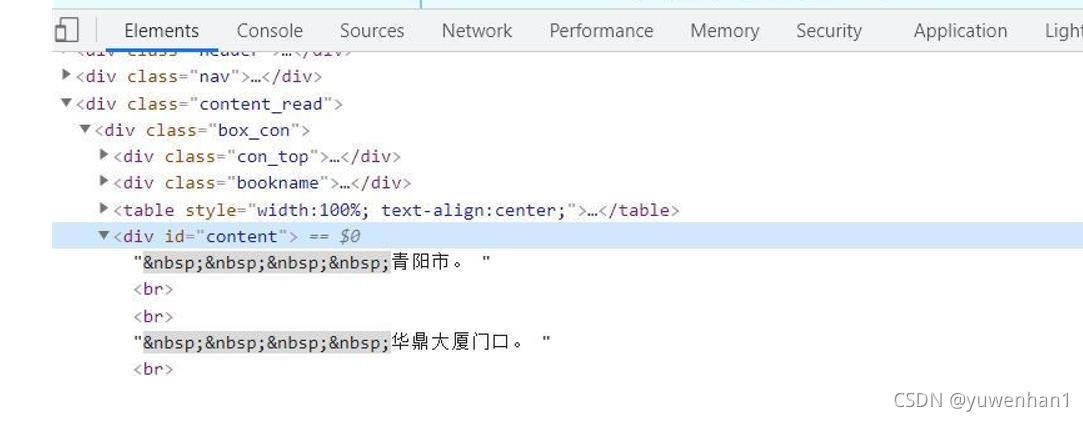
然后编写采集代码
public void getAllContent(String url) {
Document doc=util1.getDocument(url);//获取document对象,url为该正文链接
Element ml=doc.getElementById("content");//获取正文
System.out.println("当前文章内容:"+ml.toString());
}采集结果: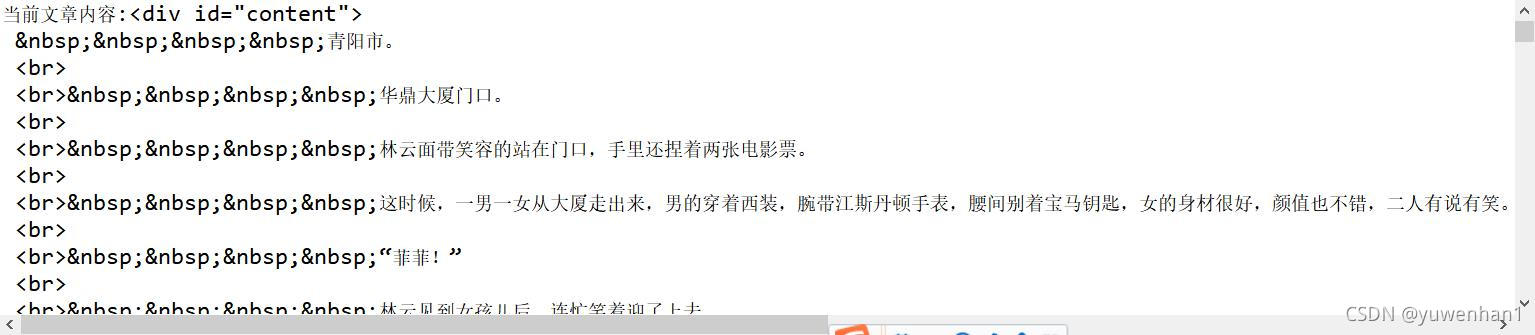
可以看到已经采集成功,这只是采集一条文章正文,自行修改代码,采集所有文章正文
出现问题:
因为循环大量采集所有文章内容,有时候会出现503错误,频繁错误,导致采集效率低下。采集方法加入代码 Thread.sleep(1 * 1000);
让采集方法一秒执行一次,经测试,没有再出现过503错误。
但是又有新的问题:
1、如果并行执行2个采集文章正文方法,503错误会出现。
2、如果只执行一个采集方法,一秒一篇正文,一部小说3000篇章节就需要50分钟,时间开销大,采集效率低,要知道3000篇章节以上的小说都是普遍存在的。我上面采集那部小说目录章节就已经是3369章,所有正文采集就需要56分钟。
3、后来测试,设置代理ip,更换浏览器标识都没有用。
4、当数据库一个表里面有1万条以上数据时,发现点击文章上下条,出现5秒响应,后期得优化一下代码。
最后看看效果:
PC端:
小说目录:
正文:
移动端:
小说目录:
正文:




